Hash sensível à localidade
Goal: Encontrar documentos com similaridade Jaccard de pelo menos t
A ideia geral do LSH é encontrar um algoritmo tal que se introduzirmos assinaturas de 2 documentos, diz-nos que esses 2 documentos formam ou não um par candidato, ou seja, a sua similaridade é maior que um limiar t. Lembre-se que estamos a tomar a semelhança de assinaturas como um proxy para a semelhança Jaccard entre os documentos originais.
Especificamente para matriz de assinatura min-hash:
- Colunas de hash da matriz de assinatura M usando várias funções de hash
- Se 2 documentos tiverem hash no mesmo balde para pelo menos uma das funções de hash podemos tomar os 2 documentos como um par de candidatos
Agora a questão é como criar diferentes funções de hash. Para isso fazemos a partição de banda.
Partição de banda

Aqui está o algoritmo:
- Dividir a matriz de assinatura em bandas b, cada banda tendo r filas
- Para cada banda, hash sua parte de cada coluna para uma tabela de hash com k baldes
- Pares de colunas candidatos são aqueles que hash para o mesmo balde para pelo menos 1 banda
- Calcadas b e r para pegar a maioria dos pares semelhantes, mas poucos pares não semelhantes
Existem poucas considerações aqui. Idealmente para cada banda queremos tomar k para ser igual a todas as combinações possíveis de valores que uma coluna pode tomar dentro de uma banda. Isto será equivalente à correspondência de identidade. Mas desta forma, k será um número enorme que é computacionalmente inviável. Por ex: Se para uma banda temos 5 linhas nela. Agora se os elementos na assinatura são inteiros de 32 bits então k neste caso será (2³²)⁵ ~ 1.4615016e+48. Você pode ver qual é o problema aqui. Normalmente k é tomado em torno de 1 milhão.
A ideia é que se 2 documentos são semelhantes então eles aparecerão como par candidato em pelo menos uma das bandas.
Opção de b & r
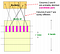
Se tomarmos b grande, ou seja, mais número de funções de hash, então reduzimos r como b*r é uma constante (número de linhas na matriz de assinatura). Intuitivamente isso significa que estamos aumentando a probabilidade de encontrar um par candidato. Este caso é equivalente a tomar um pequeno t (limite de similaridade)
Vamos dizer que a sua matriz de assinatura tem 100 linhas. Considere 2 casos:
b1 = 10 → r = 10
b2 = 20 → r = 5
>No 2º caso, há maior probabilidade de 2 documentos aparecerem no mesmo balde pelo menos uma vez, pois têm mais oportunidades (20 vs 10) e menos elementos da assinatura estão a ser comparados (5 vs 10).
>
B mais alto implica menor limiar de similaridade (maiores falsos positivos) e mais baixo b implica maior limiar de similaridade (maiores falsos negativos)
Tentemos compreender isto através de um exemplo.
Configuração:
- 100k documentos armazenados como assinatura de comprimento 100
- Matriz de assinatura: 100*100000
- Comparação de força bruta de assinaturas resultará em comparações 100C2 = 5 bilhões (bastante!)
- Deixemos pegar b = 20 → r = 5
similaridade (t) : 80%
Queremos 2 documentos (D1 & D2) com 80% de similaridade a serem hashed no mesmo balde para pelo menos uma das 20 bandas.
P(D1 & D2 idênticos numa determinada banda) = (0.8)⁵ = 0.328
P(D1 & D2 não são semelhantes nas 20 bandas) = (1-0.328)^20 = 0.00035
Isto significa que neste cenário temos ~.035% de chance de um falso negativo @ 80% documentos semelhantes.
Também queremos 2 documentos (D3 & D4) com 30% de similaridade a não ser hashed no mesmo balde para qualquer das 20 bandas (limiar = 80%).
P(D3 & D4 idênticos em uma banda em particular) = (0.3)⁵ = 0.00243
P(D3 & D4 são semelhantes em pelo menos uma das 20 bandas) = 1 – (1-0.00243)^20 = 0.0474
Isto significa que neste cenário temos ~4.74% de chance de um falso positivo @ 30% de documentos semelhantes.
Então podemos ver que temos alguns falsos positivos e poucos falsos negativos. Esta proporção irá variar com a escolha de b e r.
O que queremos aqui é algo como abaixo. Se temos 2 documentos que têm similaridade maior que o limite, então a probabilidade de eles compartilharem o mesmo balde em pelo menos uma das bandas deve ser de 1 outra banda 0.

Pior caso será se tivermos b = número de linhas na matriz de assinatura, como mostrado abaixo.

Mala generalizada para qualquer b e r é mostrada abaixo.
Escolha b e r para obter a melhor curva S i.e taxa mínima de falsos negativos e falsos positivos

ResumoLSH
- Tune M, b, r para obter quase todos os pares de documentos com assinaturas semelhantes, mas eliminar a maioria dos pares que não têm assinaturas semelhantes
- Checar na memória principal que os pares candidatos realmente têm assinaturas semelhantes