
A sua organização quer agregar e analisar dados para aprender tendências, mas de uma forma que proteja a privacidade? Ou talvez você já esteja usando ferramentas diferenciais de privacidade, mas quer expandir (ou compartilhar) seu conhecimento? Em ambos os casos, esta série de blogs é para você.
Por que estamos fazendo esta série? No ano passado, NIST lançou um Espaço de Colaboração de Engenharia de Privacidade para agregar ferramentas, soluções e processos de código aberto que suportam a engenharia de privacidade e a gestão de riscos. Como moderadores do Espaço de Colaboração, ajudamos o NIST a reunir ferramentas de privacidade diferencial sob a área temática de desidentificação. O NIST também publicou o Privacy Framework: Uma Ferramenta para Melhorar a Privacidade através do Enterprise Risk Management e um roadmap que reconhece uma série de áreas de desafio para a privacidade, incluindo o tópico de desidentificação. Agora, gostaríamos de aproveitar o Espaço de Colaboração para ajudar a fechar a lacuna do roteiro sobre a desidentificação. Nosso objetivo final é apoiar o NIST a transformar esta série em diretrizes mais profundas sobre privacidade diferencial.
Cada posto começará com casos básicos conceituais e de uso prático, destinados a ajudar profissionais como proprietários de processos de negócios ou pessoal de programas de privacidade a aprender o suficiente para serem perigosos (brincadeira). Depois de cobrir o básico, vamos analisar as ferramentas disponíveis e suas abordagens técnicas para engenheiros de privacidade ou profissionais de TI interessados em detalhes de implementação. Para que todos possam se atualizar, este primeiro post fornecerá informações sobre privacidade diferencial e descreverá alguns conceitos-chave que usaremos no resto da série.
O Desafio
Como podemos usar os dados para aprender sobre uma população, sem aprender sobre indivíduos específicos dentro da população? Considere estas duas questões:
- “Quantas pessoas vivem em Vermont?”
- “Quantas pessoas chamadas Joe Near vivem em Vermont?”
A primeira revela uma propriedade de toda a população, enquanto a segunda revela informações sobre uma pessoa. Precisamos ser capazes de aprender sobre as tendências da população, enquanto impedimos a capacidade de aprender algo novo sobre um determinado indivíduo. Este é o objetivo de muitas análises estatísticas de dados, tais como as estatísticas publicadas pelo U.S. Census Bureau, e o aprendizado de máquinas de forma mais ampla. Em cada uma dessas configurações, os modelos destinam-se a revelar tendências nas populações, não refletindo informações sobre um único indivíduo.
Mas como podemos responder à primeira pergunta “Quantas pessoas vivem em Vermont? – a que nos referiremos como uma pergunta – enquanto impedimos que a segunda pergunta seja respondida “Quantas pessoas nomeam Joe Near live in Vermont? A solução mais utilizada chama-se de-identificação (ou anonimização), o que remove informações de identificação do conjunto de dados. (Geralmente assumimos que um conjunto de dados contém informações coletadas de muitos indivíduos). Outra opção é permitir apenas consultas agregadas, tais como uma média sobre os dados. Infelizmente, agora entendemos que nenhuma das duas abordagens oferece realmente uma forte proteção de privacidade. Os conjuntos de dados desidentificados estão sujeitos a ataques de ligação à base de dados. A agregação só protege a privacidade se os grupos agregados forem suficientemente grandes e, mesmo assim, os ataques de privacidade ainda são possíveis.
Privacidade diferencial
Privacidade diferencial é uma definição matemática do que significa ter privacidade. Não é um processo específico como a de-identificação, mas uma propriedade que um processo pode ter. Por exemplo, é possível provar que um algoritmo específico “satisfaz” a privacidade diferencial.
Informalmente, a privacidade diferencial garante o seguinte para cada indivíduo que contribui com dados para análise: a saída de uma análise diferencialmente privada será aproximadamente a mesma, quer você contribua ou não com os seus dados. Uma análise diferencialmente privada é muitas vezes chamada de mecanismo, e nós a denotamos ℳ.
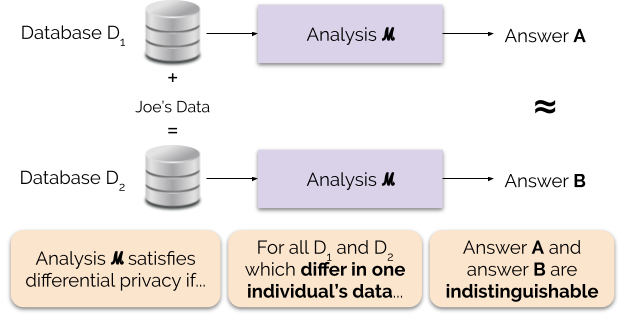
Figure 1 ilustra este princípio. A resposta “A” é computada sem os dados de Joe, enquanto a resposta “B” é computada com os dados de Joe. A privacidade diferencial diz que as duas respostas devem ser indistinguíveis. Isto implica que quem vê a saída não será capaz de dizer se os dados de Joe foram usados ou não, ou o que os dados de Joe continham.
Controlamos a força da garantia de privacidade ajustando o parâmetro de privacidade ε, também chamado de perda de privacidade ou orçamento de privacidade. Quanto menor o valor do parâmetro ε, mais indistinguíveis os resultados, e portanto mais os dados de cada indivíduo são protegidos.
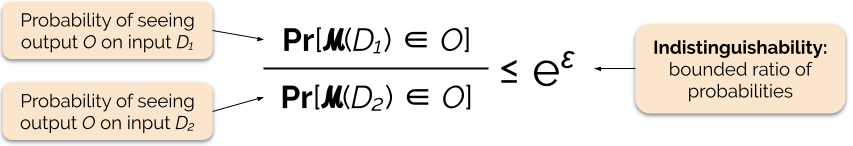
Podemos frequentemente responder a uma consulta com privacidade diferencial adicionando algum ruído aleatório à resposta da consulta. O desafio está em determinar onde adicionar o ruído e quanto adicionar. Um dos mecanismos mais utilizados para adicionar ruído é o mecanismo Laplace .
Queries with higher sensitivity require adding more noise in order to satisfy a particular `epsilon` quantity of differential privacy, and this extra noise has the potential to make results less useful. Descreveremos a sensibilidade e este tradeoff entre privacidade e utilidade com mais detalhes em posts futuros no blog.
Benefícios da privacidade diferencial
A privacidade diferencial tem várias vantagens importantes sobre as técnicas de privacidade anteriores:
- Assume que toda a informação é de identificação, eliminando a tarefa desafiadora (e às vezes impossível) de contabilizar todos os elementos de identificação dos dados.
- É resistente a ataques de privacidade baseados em informações auxiliares, de modo que pode efetivamente evitar os ataques de links que são possíveis em dados não identificados.
- É composicional – podemos determinar a perda de privacidade de executar duas análises diferencialmente privadas sobre os mesmos dados simplesmente somando as perdas de privacidade individuais para as duas análises. Composição significa que podemos fazer garantias significativas sobre privacidade mesmo quando liberarmos vários resultados de análises a partir dos mesmos dados. Técnicas como a de-identificação não são composicionais, e múltiplas liberações sob essas técnicas podem resultar em uma perda catastrófica de privacidade.
Essas vantagens são as principais razões pelas quais um profissional pode escolher privacidade diferencial em relação a alguma outra técnica de privacidade de dados. Uma desvantagem atual da privacidade diferencial é que ela é bastante nova, e ferramentas robustas, padrões e melhores práticas não são facilmente acessíveis fora das comunidades de pesquisa acadêmica. Entretanto, prevemos que essa limitação pode ser superada num futuro próximo devido à crescente demanda por soluções robustas e fáceis de usar para privacidade de dados.
Coming Up Next
Stay tuned: nosso próximo post vai se basear neste, explorando as questões de segurança envolvidas na implantação de sistemas de privacidade diferencial, incluindo a diferença entre os modelos central e local de privacidade diferencial.
Antes de irmos – queremos que esta série e as diretrizes subsequentes do NIST contribuam para tornar a privacidade diferencial mais acessível. Você pode ajudar. Se você tem perguntas sobre esses posts ou pode compartilhar seus conhecimentos, esperamos que você se envolva conosco para que possamos avançar juntos nessa disciplina.
Garfinkel, Simson, John M. Abowd, e Christian Martindale. “Compreender ataques de reconstrução de bases de dados em dados públicos.” Comunicações do ACM 62.3 (2019): 46-53.
Gadotti, Andrea, et al. “Quando o sinal está no ruído: explorando o ruído pegajoso do diffix.” 28º USENIX Security Symposium (USENIX Security 19). 2019.
Dinur, Irit, e Kobbi Nissim. “Revelando informação enquanto se preserva a privacidade.” Anais do vigésimo segundo simpósio ACM SIGMOD-SIGACT-SIGART sobre Princípios dos sistemas de banco de dados. 2003.
Sweeney, Latanya. “Demografias simples geralmente identificam as pessoas de forma única.” Saúde (São Francisco) 671 (2000): 1-34.
Dwork, Cynthia, et al. “Calibrating noise to sensitivity in private data analysis”. Teoria da conferência de criptografia. Springer, Berlim, Heidelberg, 2006.
Wood, Alexandra, Micah Altman, Aaron Bembenek, Mark Bun, Marco Gaboardi, James Honaker, Kobbi Nissim, David R. O’Brien, Thomas Steinke, e Salil Vadhan. “Privacidade diferencial: Uma cartilha para um público não técnico.” Vand. J. Ent. & Técnica. L. 21 (2018): 209.
Dwork, Cynthia, e Aaron Roth. “As bases algorítmicas da privacidade diferencial.” Fundamentos e Tendências em Informática Teórica 9, não. 3-4 (2014): 211-407.