Olá Pessoal! Neste artigo, vou descrever um algoritmo usado no Processamento de Linguagem Natural: Análise Semântica Latente ( LSA ).
As principais aplicações deste método acima mencionado são de grande alcance em linguística: Comparando os documentos em espaços de baixa dimensão (Similaridade de Documentos), Encontrando tópicos recorrentes em documentos (Modelagem Tópica), Encontrando relações entre termos (Sinotimidade de Texto).

Introdução
O modelo de Análise Semântica Latente é uma teoria de como se pode aprender o significado
representações a partir do encontro de grandes amostras de linguagem sem instruções explícitas sobre como é estruturada.
O problema em mãos não é supervisionado, ou seja, não temos etiquetas ou categorias fixas atribuídas ao corpus.
Para extrair e compreender padrões dos documentos, o LSA segue inerentemente certas suposições:
1) O significado das frases ou documentos é uma soma do significado de todas as palavras que nele ocorrem. Em geral, o significado de uma determinada palavra é uma média em todos os documentos em que ocorre.
2) O LSA assume que as associações semânticas entre palavras não estão presentes explicitamente, mas apenas latentemente na grande amostra de linguagem.
Perspectiva Matemática
Análise Semântica Latente (LSA) compreende uma certa operação matemática para obter uma visão sobre um documento. Este algoritmo forma a base da Modelação Tópica. A idéia central é pegar uma matriz do que temos – documentos e termos – e decompô-la em uma matriz separada de documentos-tópicos e uma matriz de termos tópicos.
O primeiro passo é gerar nossa matriz de documentos- termos usando o Tf-IDF Vectorizer. Ele também pode ser construído usando um Modelo de Saco de Palavras, mas os resultados são escassos e não dão nenhum significado à matéria.
Dados m documentos e n palavras em nosso vocabulário, podemos construir uma matriz A
m × n em que cada linha representa um documento e cada coluna representa uma palavra.
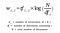
Intuitivamente, um termo tem um grande peso quando ocorre frequentemente ao longo do documento, mas raramente ao longo do corpus.
Formamos uma matriz documento-termo, A usando este método de transformação(tf-IDF) para vetorizar o nosso corpus. ( De certa forma, que o nosso modelo posterior pode processar ou avaliar, uma vez que ainda não trabalhamos com cordas!)
Mas há uma desvantagem sutil, não podemos inferir nada observando A, pois é uma matriz barulhenta e esparsa. ( Por vezes demasiado grande para ser calculado para processos posteriores).
Since Topic Modeling is inherently an unsupervised algorithm, we have to specify the latent topics before hand. É análogo ao agrupamento de K-Means de tal forma que especificamos o número de agrupamento antes.
Neste caso, realizamos uma Aproximação de Baixa Classificação usando uma técnica de Redução de Dimensão usando uma Decomposição de Valor Singular Truncada (SVD).
Decomposição de Valor Singular é uma técnica em álgebra linear que fatoriza qualquer matriz M no produto de 3 matrizes separadas: M=U*S*V, onde S é uma matriz diagonal dos valores singulares de M.
SVD truncada reduz a dimensionalidade selecionando apenas os t maiores valores singulares, e mantendo apenas as primeiras colunas t de U e V. Neste caso, t é um hiperparâmetro que podemos selecionar e ajustar para refletir o número de tópicos que queremos encontrar.
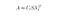
Nota: SVD Truncado faz a Redução de Dimensão e não o SVD!

Com estes vectores de documento e vectores de termo, podemos agora facilmente aplicar medidas como a semelhança co-seno para avaliar:
- a similaridade de diferentes documentos
- a similaridade de diferentes palavras
- a similaridade de termos (ou “consultas”) e documentos (o que se torna útil na recuperação de informação, quando queremos recuperar as passagens mais relevantes para a nossa consulta de pesquisa).
Closing Remarks
Este algoritmo é usado principalmente em várias tarefas baseadas em PNL e é a base para métodos mais robustos como Probabilistic LSA e Latent Dirichlet Allocation (LDA).
Kushal Vala, Junior Data Scientist at Datametica Solutions Pvt Ltd